一切为了AI 黄仁勋GTC大会发布全新DPU处理器,计算吞吐量三年跨越1000倍,重塑数据处理与存储服务新范式
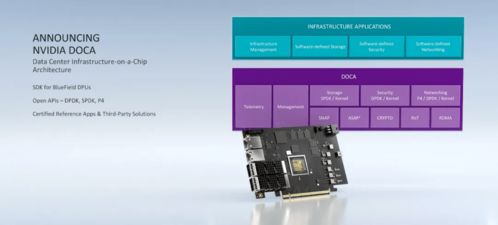
在近日举行的NVIDIA GTC大会上,创始人兼首席执行官黄仁勋发布了全新的数据处理单元(DPU)处理器,标志着人工智能基础设施领域迎来了一次重大飞跃。此次发布的核心亮点在于,新一代DPU实现了计算吞吐量在短短三年内跨越1000倍的惊人增长,这不仅是技术的指数级突破,更是黄仁勋“一切为了AI”战略愿景的集中体现。全新的DPU旨在彻底革新数据中心的数据处理与存储支持服务,为AI应用的规模化部署与高效运行提供前所未有的强大动力。
DPU:AI时代的数据中心“新引擎”
随着人工智能模型复杂度与数据量的爆炸式增长,传统以CPU为中心的数据中心架构正面临严峻挑战。数据处理、网络传输和存储I/O的瓶颈日益凸显,严重制约了AI算力的有效释放。NVIDIA推出的新一代DPU,正是为解决这一核心矛盾而生。它被设计为数据中心内的专用处理器,专门卸载和处理由CPU处理的网络、存储和安全等基础设施任务,从而让CPU和GPU能够更专注于运行AI、高性能计算等核心应用负载。黄仁勋在大会上强调,DPU已成为现代AI数据中心的第三大核心支柱,与CPU和GPU共同构成了完整的加速计算体系。
三年千倍吞吐:技术突破的里程碑
“计算吞吐量三年跨越1000倍”——这一宣言并非空谈,而是基于NVIDIA在芯片架构、片上网络(NoC)、高速互连技术以及软件栈方面的全方位创新。新一代DPU集成了更强大的Arm核心、下一代Tensor核心(针对特定基础设施AI任务进行优化),以及突破性的网络与存储接口。其内部的数据通路和处理引擎经过重新设计,能够以极低的延迟并行处理海量的数据包、存储请求和安全协议。这种性能的跃迁,意味着单个服务器节点能够以前所未有的效率处理来自成千上万个AI训练或推理任务的数据流,极大地提升了数据中心的整体利用率和能效比。
重塑数据处理与存储服务
全新DPU的发布,其深远影响在于从根本上重构了数据中心内部的数据处理与存储支持服务模式:
- 智能卸载与加速:DPU能够将虚拟化、网络功能(如OVS)、存储虚拟化(如NVMe-oF)、安全加密/解密以及入侵检测等任务从CPU完全卸载并硬件加速。这不仅释放了宝贵的CPU周期用于业务计算,更以硬件级的性能和确定性,保障了这些关键服务的低延迟和高吞吐。
- 存储性能革命:通过DPU对存储协议的深度加速,并结合NVIDIA的BlueField技术,可以实现本地NVMe存储的性能与共享存储的灵活性、可扩展性的完美统一。AI工作负载可以像访问本地磁盘一样高速访问网络化、池化的存储资源,彻底打破存储I/O瓶颈,满足AI训练中对海量数据集高速读写的苛刻需求。
- 安全性内生:安全不再是外挂功能,而是从芯片层面开始构建。DPU提供了从硬件信任根、安全启动到运行时全流量加密、微隔离的全栈安全能力,为多租户的AI云环境提供了从数据入口开始就牢不可破的安全防护。
- 云原生与AI就绪:新一代DPU的软件栈(如DOCA)与Kubernetes、容器、微服务等云原生范式深度集成,使得基础设施的配置、管理和编排能够完全自动化、弹性化,真正实现了“以应用为中心”的基础设施,让AI应用的开发、部署和运维变得前所未有的敏捷。
赋能未来AI基础设施
黄仁勋所描绘的“一切为了AI”的蓝图,正在通过像DPU这样的核心硬件创新一步步变为现实。这款吞吐量实现千倍跨越的新处理器,不仅仅是单点技术的突破,更是对整个AI计算生态的系统性升级。它使得构建超大规模、高效能、高安全且易于管理的AI数据中心成为可能,为下一波人工智能浪潮——无论是万亿参数的大模型训练,还是实时、复杂的边缘AI推理——提供了坚实而灵活的基础设施基石。从云端到边缘,NVIDIA正通过其全栈计算方案,全力加速各行各业的智能化转型,而全新的DPU无疑是这条道路上最关键的动力组件之一。
如若转载,请注明出处:http://www.kjifkj.com/product/69.html
更新时间:2026-06-19 18:44:33